【全部更新完毕】2024长三角数学建模B题思路代码文章教学 |
您所在的位置:网站首页 › 人工智能 数学问题 › 【全部更新完毕】2024长三角数学建模B题思路代码文章教学 |
【全部更新完毕】2024长三角数学建模B题思路代码文章教学
|
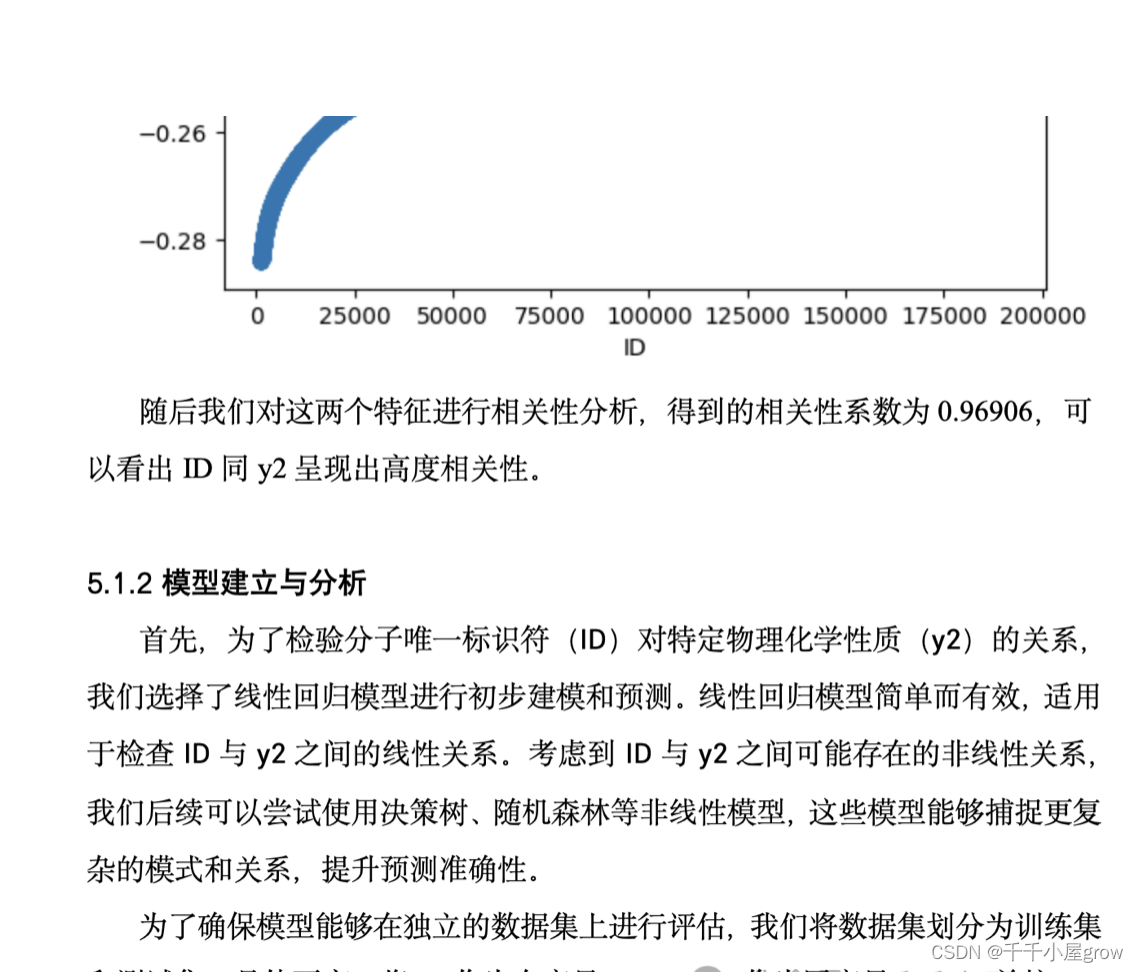
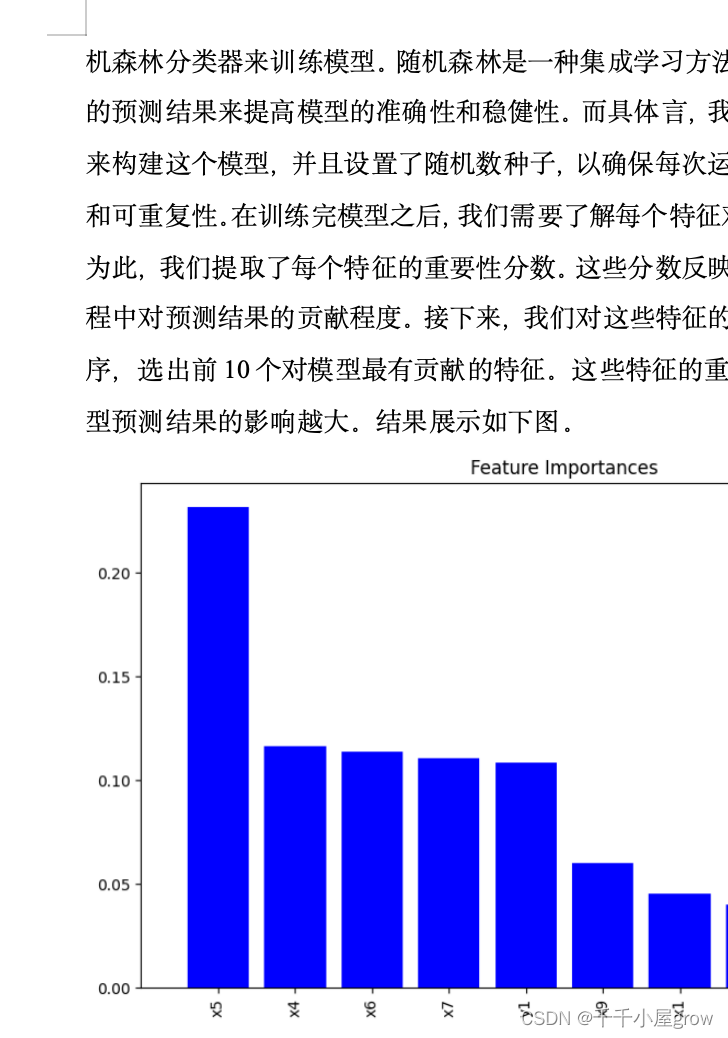
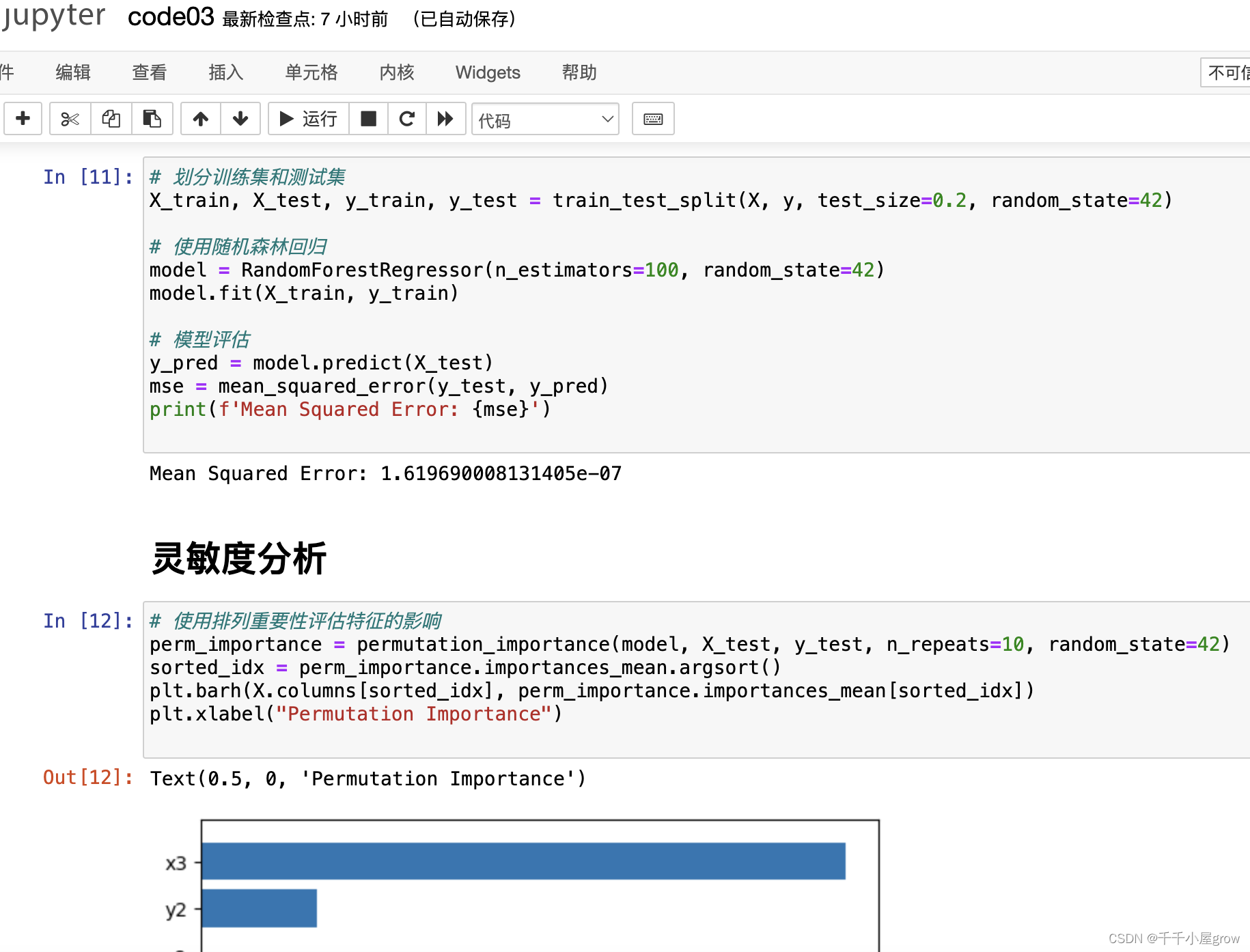
利用机器化学家平台解决化学实验中的关键问题 摘要 随着物理和化学研究对象的日益复杂化和高维化,传统研究范式因局限于“穷举”、“试错”和“重复”等手段,常常在庞大的化学空间中止步于局部最优。中国科技大学的机器化学家平台突破了这一限制,利用大数据与智能模型的双驱动,实现了化学合成、表征和测试的全流程智能化。该平台通过先进的智能化学大脑,结合机器学习、量子化学和贝叶斯优化等方法,从海量数据中汲取知识并制定实验方案,显著提升了化学研究的效率和创新能力。本文旨在利用机器化学家平台提供的数据集,通过数据分析和建模的方法解决五个关键问题,包括数据预处理、预测模型建立、特征指标选择和模型优化,最终提高化学实验的全局优化能力,并提供准确的物理化学性质和分子类别的预测结果。 在本文中,探索了分子唯一标识符(ID)与特定物理化学性质(y2)之间的关系。首先进行数据预处理,包括缺失值填充、异常值检测与处理以及特征工程,确保数据质量。发现ID与y2呈现明显的非线性关系,因此采用了非线性模型。通过线性回归初步探索了线性关系,随后采用了决策树和随机森林等更复杂的模型。数据集分为训练集和测试集,模型性能通过均方误差评估,初步模型表现良好。 随后在解决问题二的过程中,我们对数据进行了预处理,以确保数据的准确性和可靠性。首先,我们进行了数据预处理。随后,进行了特征工程,从数据中提取出与目标变量最相关的十条特征,以用于后续预测模型的构建。接着,我们通过绘制相关性矩阵图对特征之间的相关性进行了分析,确定了与目标变量最相关的特征,并进行了异常值的可视化展示,以更好地理解数据的分布情况。在此基础上,我们采用线性回归模型对数据进行训练,并对模型进行了预测和评估。最终的结果表明,我们的模型在测试集上具有较高的泛化能力和预测精度。 对问题三而言,采用了与问题二相同的方法进行了数据预处理。接下来,在建模与求解过程中,采用皮尔逊相关系数。通过计算特征与目标变量之间的相关性,筛选出与目标变量高度相关的特征,并构建了相应的特征集和预测数据集。随后,建立了随机森林回归模型进行预测,在训练完成后,均方误差达到了10的负7次。为进一步分析模型的灵敏性,采用了排列重要性方法评估特征在模型中的影响力,并通过条形图可视化了特征的重要性排序结果。结果显示,模型的预测性能主要依赖于少数几个重要特征,其中特征x3 影响最大,其次是 y2,而其他特征的重要性相对较低。 在问题四的建模与求解过程中,首先进行了数据预处理,采用随机森林分类器训练模型,包括了100棵决策树并设置了随机数种子以确保结果的一致性。通过提取每个特征的重要性分数并降序排序,选出对模型最有贡献的前10个特征。随后建立模型并进行了性能评估,将数据集划分为训练集和测试集,使用随机森林分类器进行分类,通过准确率评估模型性能,并进行了模型的重新训练。最后,对新数据进行预测并将结果写入指定文件,确保预测结果的记录和分享。整个过程中,通过特征重要性分析和性能评估,找到对模型预测最重要的特征,为模型的优化和预测提供了有力支持。 对于问题五来说,在数据预处理阶段,我们采用了LabelEncoder 对目标变量进行编码,并选择了 XGBoost 分类器进行特征选择和模型训练。经过缩放处理的特征数据和编码后的目标变量用于训练模型,而提取的特征重要性分数进一步揭示了各个特征在模型中的贡献程度。在模型建立与结果分析阶段,我们采用 XGBoost 回归模型对目标变量进行预测,并评估模型性能。通过这些步骤,我们能够获取对未知数据的预测结果,并进一步优化模型以提高预测精度。采用的优化方法包括模型调参、特征工程和集成学习技术等,这些方法有助于提高模型的性能和泛化能力,为解决实际问题提供了更好的支持。 关键词:机器化学家平台、数据分析、特征工程、模型优化、随机森林、线性回归 ##【腾讯文档】2024长三角助攻合集 ### https://docs.qq.com/doc/DVWp1dmxDb2ZReWFT二、问题分析 2.1任务一的分析 任务一旨在探究分子的唯一标识符(id)与特定物理化学性质(y2)之间的关系,并尝试使用id预测y2。为了尽可能提高预测结果的准确性,首先进行数据预处理,处理缺失值和异常值;然后通过特征工程将id转换为数值型或类别型特征;接着进行统计分析和可视化分析以识别id与y2之间的潜在关联;随后选择合适的线性或非线性模型进行预测,并通过交叉验证评估模型的稳定性和准确性;最后,通过优化模型参数,使用均方误差(MSE)和平均绝对误差(MAE)等指标评估模型性能,确保其预测效果。 2.2任务二的分析 任务二需要从多达100个物理化学性质中选择不超过10个最重要的特征来预测y1,以建立有效的预测模型来预测化学分子的特定物理化学性质y1。在数据预处理阶段,缺失值和异常值的处理是必不可少的,以确保数据的准确性和鲁棒性。另外,数据归一化也是一个重要的步骤,特别是考虑到不同物理化学性质的量度可能存在差异。在特征选择阶段,可以利用统计方法如相关系数评估特征与目标变量之间的相关性,也可以借助自动化特征选择工具来确定最具影响力的特征集。这些工具包括递归特征消除和基于模型的选择方法。最后,在建立模型阶段,选择适当的模型是至关重要的。可以根据所选特征的类型和性质来选择模型,包括线性回归、支持向量机、决策树或集成方法如随机森林。考虑到可能存在复杂的非线性关系,神经网络也是一个值得考虑的选择。在模型评估方面,交叉验证是一种常用的方法来评估模型的预测能力,而不同的性能指标如均方误差(MSE)、均方根误差(RMSE)和决定系数(R²)则可以用来评估模型的准确性和拟合度。 2.3任务三的分析 任务三要求在问题二的基础上,对y3特征进行预测,同时,需要研究这些特征指标中,哪些对y3的预测结果影响较大,并进行灵敏度分析。首先,我们需要进行函数关系分析,以确定哪些特征与目标变量 y3 存在显著的相关性或因果关系。在这个分析过程中,我们需要考虑特征与目标变量之间的线性关系以及可能存在的非线性关系,以全面理解它们之间的关联。其次,我们进行特征的重要性与灵敏度分析,以确定对 y3 预测最为关键的特征。通过灵敏度分析,我们能够了解各个特征对预测模型输出的影响程度,即当改变一个输入特征时,模型输出会如何变化。 2.4任务四的分析 问题四的分析需要通过103个物理化学特征(y1至y3和x1至x100)来预测化学分子的类别,这是一个典型的分类问题。首先,需要探索这些特征与分子类别之间的关系,识别出哪些特征具有较强的预测能力。接下来,通过特征选择方法,如特征重要性评估或递归特征消除(RFE),选出对模型最有帮助的特征。然后,选择适合的分类模型(如逻辑回归、支持向量机、决策树、随机森林或神经网络),并进行模型的训练、验证和调优。最后,通过排列重要性或部分依赖图等方法分析各特征对预测结果的影响,进行灵敏度测试,以确定哪些特征对模型预测最关键。 2.5任务五的分析 问题五是一个开放性问题,鼓励使用创新的方法来提高模型的预测精度,超越传统的特征选择和简单的模型调优。以下将详细介绍一些高级技术和方法,以及如何应用它们来提高预测性能,并对y1, y2, y3以及类别class进行重新预测。 可以采用集成学习的算法如:Bagging和Boosting方法。它们通过逐步减少模型的误差,显著提高了模型的预测能力。混合模型通过组合多种不同的模型,将一层或多层模型的输出作为另一个模型的输入。可以使用线性回归、决策树和神经网络的组合,通过Stacking技术整合它们的优点,得到更强的预测模型。通过创建原始特征的多项式和交互项,可以帮助线性模型捕捉更多的非线性关系。这些新特征能够揭示数据中的复杂模式,提高模型的预测能力。使用自动特征工程工具如Featuretools,可以从数据集中自动生成新的特征。
|


【本文地址】
今日新闻 |
推荐新闻 |